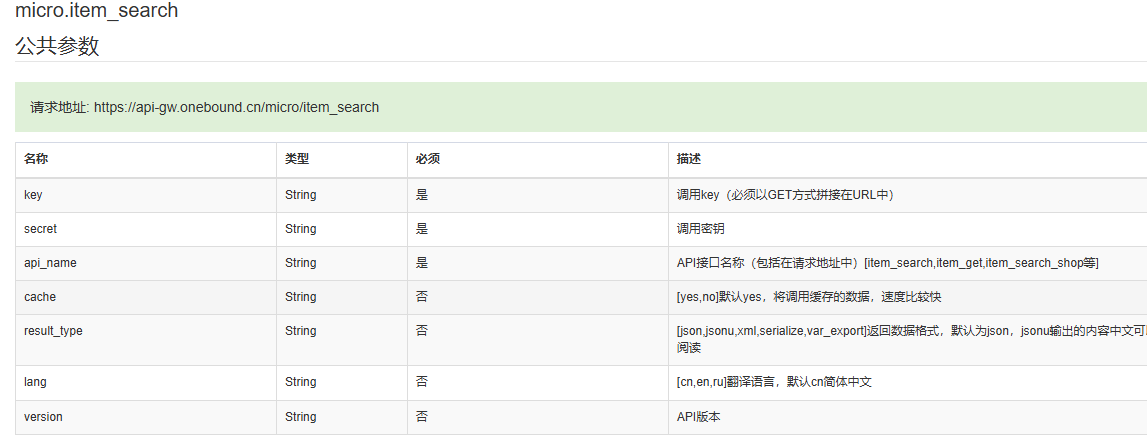
微店作为国内知名的电商平台,提供了丰富的商品资源和强大的API接口,方便开发者获取商品信息。本文将详细介绍如何使用 Python 编写爬虫程序,通过微店的 micro.item_search 接口爬取商品数据,并确保爬虫行为符合平台规范。
一、环境准备
(一)Python 开发环境
确保你的系统中已安装 Python(推荐使用 Python 3.8 及以上版本)。
(二)安装所需库
安装 requests 库,用于发送 HTTP 请求。可以通过以下命令安装:
bash
pip install requests
。二、获取 API 权限
(一)注册开发者账号
在微店开放平台注册一个开发者账号,并创建应用以获取 API 凭证(如 App Key 和 App Secret)。这些凭证是调用 API 接口所必需的。
(二)获取 Access Token
许多 API 接口调用需要使用 Access Token。可以通过以下代码获取:
Python
import requests
client_id = 'YOUR_CLIENT_ID'
client_secret = 'YOUR_CLIENT_SECRET'
auth_url = 'https://open.weidian.com/api/oauth2/token'
auth_payload = {
'grant_type': 'client_credentials',
'client_id': client_id,
'client_secret': client_secret
}
auth_response = requests.post(auth_url, data=auth_payload)
auth_data = auth_response.json()
access_token = auth_data['access_token']
。三、编写爬虫代码
(一)调用 micro.item_search 接口
以下是使用 Python 的 requests 库调用微店关键词搜索接口的示例代码:
Python
import requests
def search_items(keyword, page=1, page_size=10):
url = "https://open.weidian.com/openapi/item/search"
headers = {
"Authorization": f"Bearer {access_token}",
"Content-Type": "application/json"
}
params = {
"keyword": keyword,
"page": page,
"page_size": page_size
}
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
return response.json()
else:
print(f"请求失败,状态码: {response.status_code}")
return None
。(二)解析返回数据
接口返回的 JSON 数据中包含商品的详细信息。以下是一个解析响应数据的示例:
Python
def parse_search_results(data):
if data and data.get('code') == 0:
items = data.get('data', {}).get('items', [])
for item in items:
print(f"商品ID: {item.get('id')}")
print(f"商品标题: {item.get('title')}")
print(f"商品价格: {item.get('price')}")
print(f"商品图片URL: {item.get('image_url')}")
else:
print("未能获取商品数据")
。(三)完整代码示例
将上述功能整合到主程序中,实现完整的爬虫程序:
Python
if __name__ == "__main__":
keyword = "女装"
search_results = search_items(keyword, page=1, page_size=10)
if search_results:
parse_search_results(search_results)
else:
print("未获取到搜索结果")
。四、注意事项
(一)遵守法律法规
在进行网络爬虫开发时,必须遵守相关法律法规,不得侵犯数据隐私和版权。
(二)尊重 API 限制
合理使用 API 接口,避免频繁请求导致服务拒绝。
(三)异常处理
在实际应用中,应增加异常处理逻辑,以应对网络请求失败、数据解析错误等情况。
五、总结
通过上述步骤,你可以使用 Python 爬虫技术高效地获取微店商品的搜索结果数据。在实际开发中,建议根据具体需求调整代码逻辑,例如增加分页处理、过滤条件等,以满足更多业务场景。
如遇任何疑问或有进一步的需求,请随时与我私信或者评论联系。